Vero: An Open RL Recipe for General Visual Reasoning
ECCV, 2026
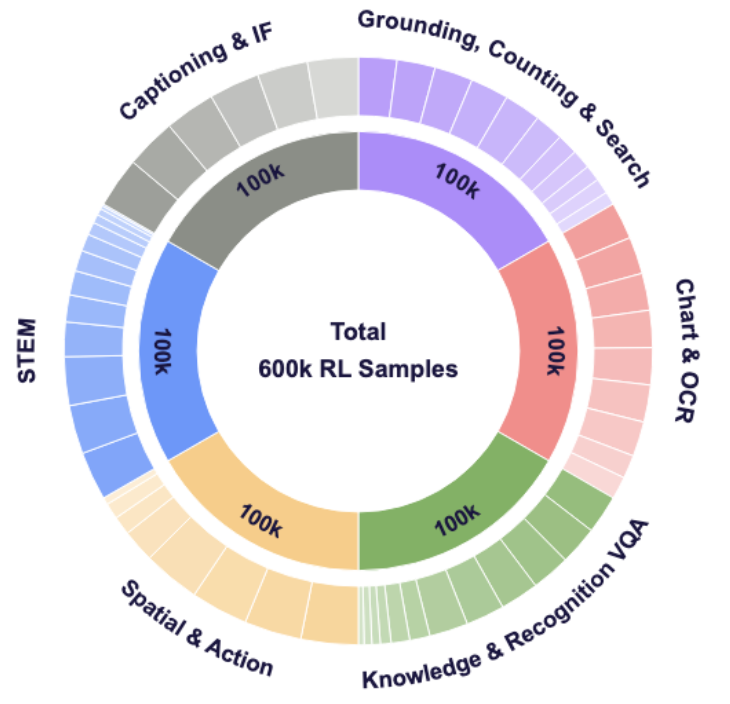
We introduce Vero, a family of fully open vision-language models (VLMs) designed for general visual reasoning across diverse domains such as charts, science, and spatial understanding. By scaling reinforcement learning (RL) data with the 600K-sample Vero-600K dataset and task-routed rewards, Vero achieves state-of-the-art performance on 30 challenging benchmarks, demonstrating that broad data coverage is the key driver of strong RL scaling. All data, code, and models are publicly released.
Gabriel Sarch, Linrong Cai, Qunzhong Wang, Haoyang Wu, Danqi Chen, Zhuang Liu
Download Paper | Download Slides